🚨 The Outage That Shook the Cloud
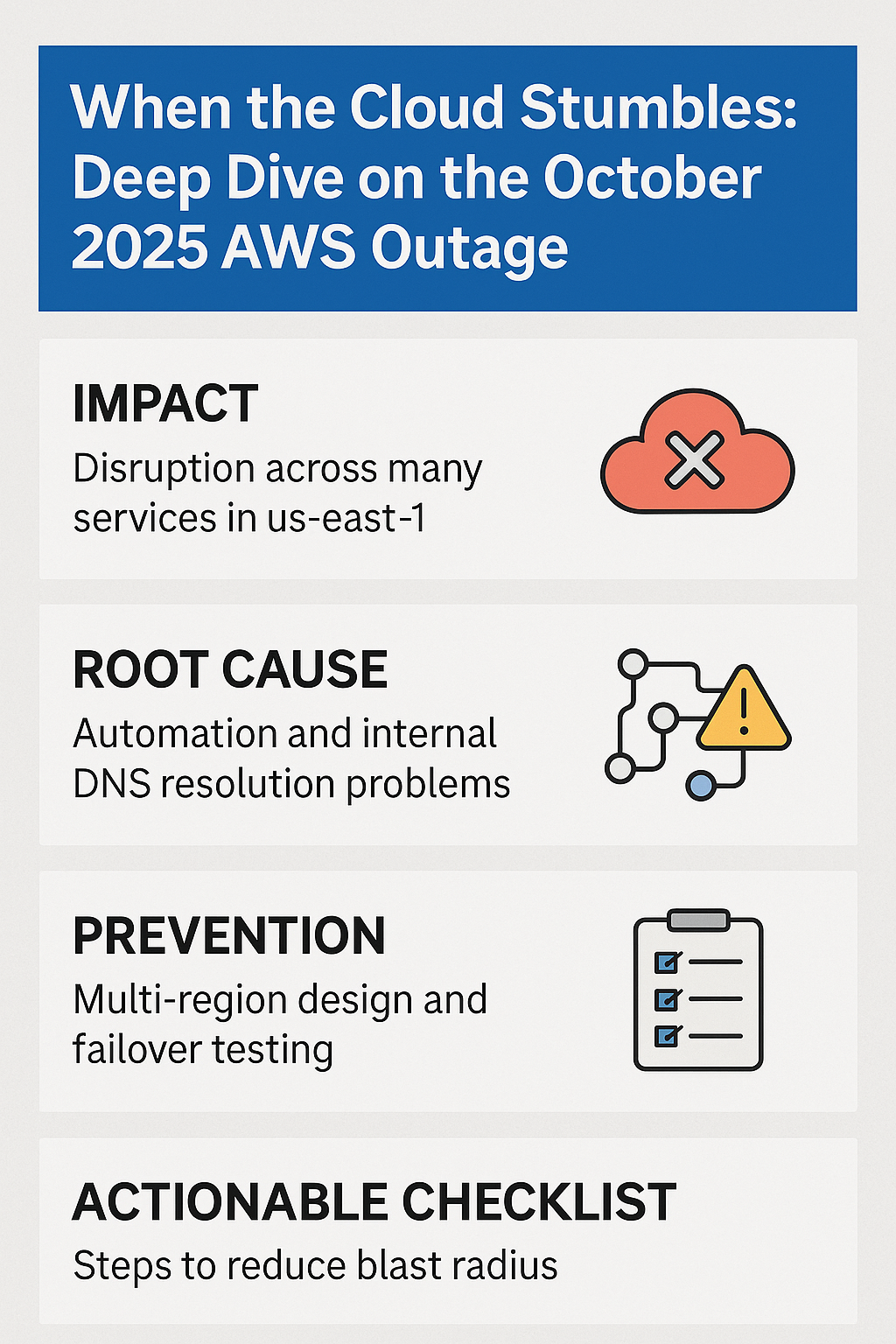
Even the most reliable systems can stumble. On October 19–20, 2025, Amazon Web Services—arguably the backbone of the modern internet—experienced a widespread outage in its us-east-1 region.
It began quietly: a few elevated error rates on DNS resolution and control-plane requests. Within minutes, that subtle tremor rippled outward, toppling services dependent on DynamoDB, EC2, Lambda, and even core management APIs.
Suddenly, global traffic began to slow, then choke.
Monitoring dashboards went red. Alerts exploded in Slack channels. Teams from Mumbai to New York scrambled to reroute production workloads as entire service stacks froze.
🌍 Real-Time Chaos: What Engineers Saw in the Wild
This wasn’t just another blip; this was a global systems lesson unfolding in real time.
🕹️ Authentication & API Failures
A leading Indian fintech’s user logins began failing without explanation. Every request hit an internal service that queried DynamoDB for session tokens. When DynamoDB’s endpoints stopped resolving, the API gateway returned cryptic 5xx errors.
Within 30 minutes, customers flooded Twitter, complaining that “the app is stuck on loading.” Engineers, thinking it was a new code push, began rolling back deployments—unaware that AWS itself was the culprit.
💳 Retail and Payments Chaos
Several e-commerce platforms reported failed checkout processes. Cart services relying on synchronous DynamoDB writes couldn’t persist session data.
A major Indian payments aggregator logged over 12,000 failed UPI transactions in a single hour, losing nearly ₹1.2 crore in potential revenue before rerouting to cached price lists and local failover instances.
🧠 Internal Automation Breakdowns
CI/CD pipelines using Jenkins on EC2 froze mid-deploy. ArgoCD sync jobs hung for hours as their API calls timed out. Even observability stacks—Prometheus, Grafana, and Datadog—began producing false alerts because they couldn’t reach AWS’s control plane.
📦 Queues and Backlogs
Once AWS mitigated the DNS and control-plane issues, thousands of services resumed—but now faced mountains of queued data.
Message brokers like SQS and Kafka had accumulated massive payloads, delaying reconciliation and log indexing for up to eight hours post-recovery.
🧩 The Root Cause, Explained Like a Systems Engineer
AWS later confirmed that DNS resolution issues inside us-east-1 cascaded across multiple internal services.
Here’s the simplified breakdown of the domino effect:
- DNS subsystem misconfiguration within the regional network control plane introduced latency and resolution errors.
- Services relying on those endpoints (like DynamoDB, EC2 metadata, ECR, etc.) began timing out.
- Dependent AWS automation layers (CloudFormation, Control Tower, Service Catalog) failed health checks and entered degraded states.
- Customers’ applications—built atop these services—experienced cascading failures.
The combination of DNS failure + internal automation malfunction created a circular dependency: AWS services waiting for each other to recover.
Even once DNS was restored, delayed replication and message backlogs meant several hours of partial recovery before full stability returned.
🔥 Real Business Impact (The Human Side of Infrastructure)
While AWS was triaging the incident, the business side felt the real damage:
- E-commerce loss during prime sale hours across India and Southeast Asia exceeded ₹8 crore across multiple platforms.
- B2B SaaS vendors faced angry clients demanding SLA credits for downtime they couldn’t prevent.
- Support costs spiked as companies fielded thousands of “Why is your app down?” tickets.
- Brand trust eroded — users don’t distinguish between an AWS outage and your product failure.
It was, quite literally, a masterclass in shared responsibility — one where customers realized that resilience isn’t AWS’s job alone.
⚙️ Why AWS Outages Hurt So Many So Fast
AWS’s architecture is incredibly resilient, but customers’ design patterns often are not. Here’s why:
- Many workloads are concentrated in us-east-1, because it’s the oldest region and default for most deployments.
- DNS is a global dependency. When it hiccups, everything—control plane, EC2, S3, DynamoDB—feels it.
- Application code often assumes region-local stability, without retry strategies or fallbacks.
- Cloud-native monitoring often depends on the same region that’s failing.
When all these assumptions collide, even a 20-minute service degradation can look like a total blackout.
🧠 What We Learned: The Reality of Cloud Dependency
The outage didn’t just break systems; it broke assumptions:
- “AWS never goes down.” → False. Every system can fail.
- “We’re multi-AZ, so we’re safe.” → Regional DNS failure ignores AZ boundaries.
- “Our monitoring will alert us.” → Not if your monitoring depends on the same region.
True resilience isn’t redundancy within a single region. It’s redundancy across independent failure domains—geographically and logically.
🛡️ Prevention Blueprint: How to Survive the Next AWS Outage
Now for the part that matters — how to make sure your systems don’t collapse with the next global hiccup.
🏗️ 1. Go Multi-Region or Multi-Cloud for Critical Systems
Design your production control plane across at least two AWS regions—one active, one hot standby.
Use DynamoDB Global Tables, cross-region S3 replication, and Route53 failover routing.
Even if replication adds minor latency, it beats complete downtime.
# Example: Multi-region DynamoDB Global Table
Resources:
UserSessions:
Type: AWS::DynamoDB::GlobalTable
Properties:
TableName: user-sessions
Replicas:
- Region: us-east-1
- Region: ap-south-1
🌐 2. DNS Health and Fallback Testing
Use multi-provider DNS. Route53 as primary, Cloudflare or NS1 as secondary.
Set low TTLs (30–60s) and automate DNS failover tests monthly.
Monitor DNS resolution latency as a metric — not just endpoint uptime.
🧩 3. Build for Graceful Degradation
If backend dependencies fail:
- Serve cached pages.
- Allow read-only mode.
- Queue writes for replay later.
Feature-flag non-critical services like image uploads, reports, or analytics when backend health drops below threshold.
📊 4. Observability: Beyond Green Dashboards
Track business metrics, not just infra metrics.
For example:
- UPI success rate < 98% = alert
- Checkout conversion drop > 10% = incident
These catch hidden degradation before your SRE dashboard does.
⚡ 5. Avoid Retry Storms
During outages, every client retry adds load to already failing systems.
Use exponential backoff with jitter and circuit breakers (Resilience4j, Polly, etc.) to prevent “self-inflicted DDoS.”
🧰 6. Regular Chaos and Failover Testing
Don’t wait for AWS to test your resilience.
Simulate outages:
- Break DNS resolution using a local resolver block.
- Disable access to DynamoDB endpoints temporarily.
- Measure failover times and recovery behavior.
If your system can’t fail gracefully in a test, it won’t in production.
🧾 7. Post-Outage Discipline
Every outage should result in:
- A blameless postmortem
- Documented root cause and remediation
- Playbook updates
- Follow-up simulation within 30 days
Incident management maturity comes from habit, not panic.
🧮 Summary Table: From Weakness to Resilience
| Area | Weak Design | Resilient Design |
|---|---|---|
| Region Dependence | Single region (us-east-1) | Active/Active across 2 regions |
| DNS | One provider | Multi-provider, failover routing |
| Data Layer | Region-local DynamoDB | Global Tables or async replication |
| Monitoring | Region-bound | Multi-region, KPI-based |
| CI/CD | Same-region runners | Remote runners + offline fallback |
| Recovery | Manual | Automated failover runbooks |
💡 What Indian Enterprises Should Do Right Now
For companies operating in India, the lesson is sharper:
- Don’t centralize in one AWS region to save cost; ap-south-1 + backup in ap-southeast-1 is the minimum.
- Run UAT or pre-prod in a different region to detect dependency coupling early.
- Budget for resilience. Outages cost more than redundancy ever will.
This is not a cloud cost problem—it’s a business continuity problem.
🧠 Final Thoughts
The October 2025 AWS outage was a painful reminder that even the giants can fall, and when they do, the world feels the shock.
But resilience isn’t about avoiding failure—it’s about absorbing it, surviving it, and recovering fast enough that users barely notice.
If your architecture can gracefully handle a DNS blackout, a queue backlog, or a temporary control-plane stall, you’ve built something that transcends provider reliability.
Cloud outages will continue to happen.
The question is: Will your systems bend, or will they break?