Introduction — The Heart of Modern Cloud Infrastructure
Kubernetes has become the de facto standard for container orchestration. Whether you’re deploying microservices or managing enterprise-scale clusters, understanding Kubernetes architecture is critical. Every time a pod starts, scales, or self-heals — it’s the control plane and node components working in perfect harmony.
In this 2025 technical deep dive, we’ll explore how each part of the Kubernetes architecture functions, how the control plane and nodes communicate, and what’s changed in recent versions.
High-Level Architecture Overview
A Kubernetes cluster consists of two logical parts:
- Control Plane — The brain of the cluster, responsible for global decisions (scheduling, scaling, healing).
- Worker Nodes — The muscle that runs the actual workloads (pods and containers).
Communication between them happens via the Kubernetes API. The API Server is the central hub — it exposes REST endpoints for kubectl, controllers, and internal services.
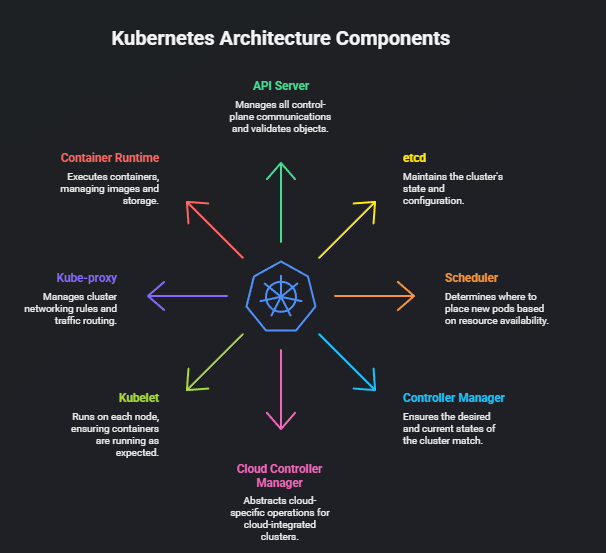
Visual Summary (Conceptual)

Control Plane Components
1. API Server — The Front Door of Kubernetes
The kube-apiserver is the entry point for all control-plane communication. It exposes a RESTful API, processes YAML/JSON manifests, and validates objects before committing them to the cluster state stored in etcd.
Key responsibilities:
- Authentication and authorization (RBAC, tokens, certificates)
- Validation and admission control
- State persistence via etcd
- Serving watch requests for cluster events
In simple terms, the API Server is the traffic controller of Kubernetes. Every command (kubectl apply, controller updates, or scheduler decisions) goes through it.
2. etcd — The Source of Truth
etcd is a highly consistent key-value store that maintains the cluster’s state. When you deploy a pod, its desired state is stored in etcd, and the controllers work continuously to match the actual state to this desired one.
Key points:
- Uses the Raft consensus algorithm
- Stores all configuration and secrets in key-value form
- Must be backed up regularly (critical for disaster recovery)
As of Kubernetes 1.30+, etcd performance and snapshot management have been improved, and many production setups now run it on dedicated nodes for reliability.
3. Scheduler — The Decision Maker
The kube-scheduler watches for newly created pods without assigned nodes and decides where to place them.
Scheduling decisions depend on:
- Resource availability (CPU, memory)
- Node selectors and affinities
- Taints and tolerations
- Pod topology spread constraints
Advanced clusters now integrate descheduler and bin-packing plugins for optimized workload placement and cost savings.
4. Controller Manager — The Cluster Maintainer
The kube-controller-manager runs multiple controllers that reconcile desired and current states. Think of controllers as background loops ensuring everything is as declared.
Common controllers include:
- Node Controller — tracks node health
- ReplicaSet Controller — ensures the desired number of pods
- Endpoint Controller — maintains service endpoints
- Namespace Controller — manages namespaces and cleanup
Each controller continuously checks etcd for changes and takes corrective actions (create/delete pods, reassign workloads, etc.).
5. Cloud Controller Manager — Cloud-Specific Logic
For clusters integrated with cloud providers (AWS, GCP, Azure), the cloud-controller-manager abstracts cloud-specific operations:
- Node lifecycle management
- Load balancer provisioning
- Persistent volume (EBS, PD, AzureDisk) attachment/detachment
Cloud providers now also support out-of-tree CCMs, which can be upgraded independently from Kubernetes itself.
Node Components — Where Workloads Run
1. Kubelet — The Node Agent
The kubelet runs on every worker node. It ensures containers are running as expected and matches the node’s actual state to the control plane’s desired state.
Key functions:
- Receives PodSpecs from the API Server
- Interacts with the container runtime (containerd, CRI-O)
- Performs liveness/readiness checks
- Reports node and pod status back to the control plane
In short, kubelet is the node-level operator for Kubernetes.
2. Kube-proxy — The Network Router
The kube-proxy manages cluster networking rules. It handles virtual IP translation and routing between services and pods.
Modes of operation:
- iptables mode — most common, relies on Linux netfilter
- IPVS mode — scales better with large clusters (recommended for production)
Modern clusters often combine kube-proxy with service meshes (Istio, Linkerd) or eBPF-based solutions (Cilium) for advanced traffic management.
3. Container Runtime — The Execution Engine
Kubernetes no longer depends on Docker directly. Since Kubernetes 1.24, containerd and CRI-O are the main CRI-compliant runtimes.
The runtime’s job is to:
- Pull container images
- Start and stop containers
- Manage container storage and networking interfaces
As of 2025, containerd dominates Kubernetes deployments for its performance, CRI compliance, and lower overhead.
Cluster Communication Flow
Here’s how these components interact when you deploy a new workload:
- User runs
kubectl apply -f pod.yaml. - The API Server validates the manifest and saves it in etcd.
- The Scheduler detects an unscheduled pod and assigns it to a node.
- The kubelet on that node receives the PodSpec, pulls the container image, and starts the container via containerd.
- The Controller Manager ensures the pod matches its desired replica count.
- The kube-proxy updates network rules to route traffic to the new pod.
This continuous reconciliation loop — desired vs. actual state — is the essence of Kubernetes automation.
High Availability (HA) and Modern Enhancements (2025)
Kubernetes architecture has evolved significantly:
- HA Control Planes: Multi-master setups using stacked etcd or external etcd clusters.
- Improved Network Stack: eBPF replaces iptables in high-performance clusters.
- Ephemeral Containers: Debugging live pods without restarts.
- Sidecar containers: Now officially supported in Kubernetes 1.30+ as first-class citizens.
Enterprises are also embracing Kubernetes Operations (KOps), Cluster API (CAPI), and GitOps for lifecycle automation and declarative cluster management.
Conclusion — Why Understanding Architecture Matters
Knowing the inner workings of Kubernetes isn’t optional for DevOps engineers — it’s essential. Every deployment, rollout, or scaling event depends on a deep coordination between these control plane and node components.
When you understand how API Server, etcd, and kubelet interact, you can troubleshoot cluster issues faster, design resilient systems, and optimize workloads at scale.
In short — if the control plane is the brain, and the nodes are the hands, Kubernetes is the nervous system that connects your entire cloud-native world.
Recommended Reading:
- Kubernetes Documentation: Architecture Overview
- Kubernetes Scheduling Profiles (Advanced)
- Kubernetes Container Runtime Interface (CRI)
Author: Chandan Kumar
Website: outoftheboxtech.in