
Let me be real with you. When I first started working with Kubernetes seriously, I treated etcd like a black box. I knew it was there, I knew the control plane used it, and I knew I should not mess with it. But the moment one of our etcd nodes went down in a production cluster and we had no idea how to recover it cleanly, I realised I had been ignoring the most critical piece of the entire Kubernetes brain.
If you’re running Kubernetes in production and you haven’t taken the time to truly understand how etcd works and how to set it up properly, this post is for you.
What Even Is etcd? (The Short Version)
etcd is a distributed key-value store. In the Kubernetes world, it’s the place where the entire cluster state lives — every pod, every deployment, every secret, every config. When you run kubectl get pods, the API server is going to etcd and fetching that data.
Think of it like this: if Kubernetes is a city, etcd is the land records office. Every decision about what exists and what doesn’t passes through it.
So yes, losing etcd = losing everything.
Before You Start: What You Actually Need
To set up a proper etcd cluster (not just a single-node setup), you need at least 3 nodes. Always odd numbers — 3, 5, or 7. This is because etcd uses a consensus algorithm called Raft, and it needs a majority of nodes (called a quorum) to agree before committing any data.
- With 3 nodes, you can handle 1 failure
- With 5 nodes, you can handle 2 failures
- With 7 nodes, you can handle 3 failures — but you also add more write latency
Most production setups are happy with 3 or 5 nodes.
For this guide, we’ll set up a 3-node etcd cluster on Ubuntu 22.04 as an external etcd setup (the production-grade way, separate from Kubernetes).
Each node:
| Node | Hostname | IP |
|---|---|---|
| Node 1 | etcd-01 | 192.168.1.11 |
| Node 2 | etcd-02 | 192.168.1.12 |
| Node 3 | etcd-03 | 192.168.1.13 |
Ports needed: 2379 (client) and 2380 (peer) open between all nodes.
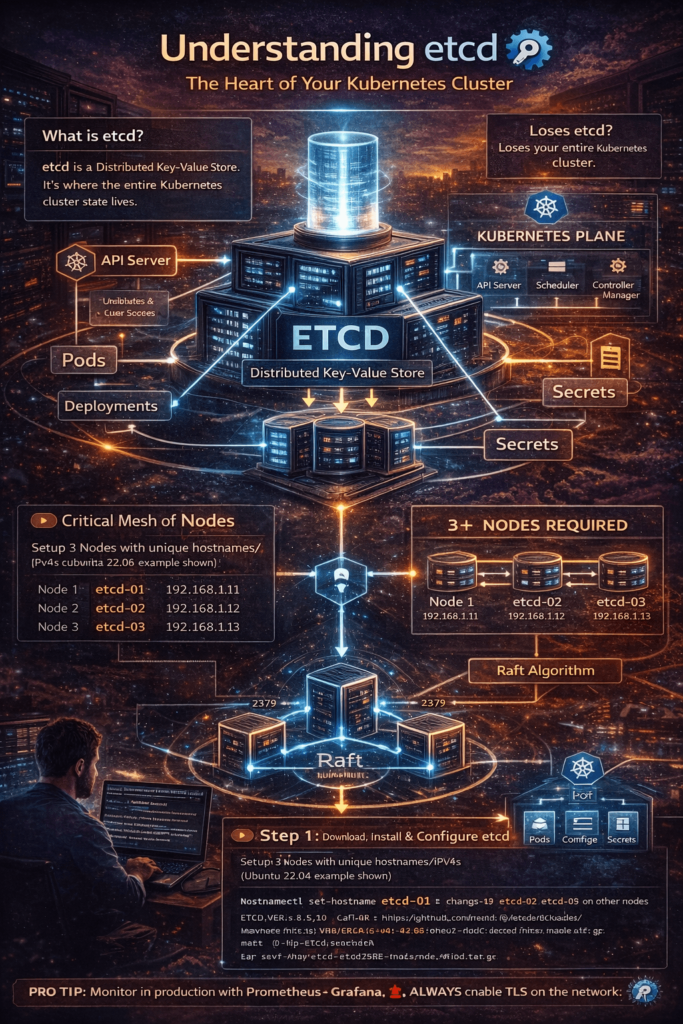
Step 1: Set Hostnames and Update /etc/hosts
Do this on all 3 nodes:
# On each node, set the respective hostname
hostnamectl set-hostname etcd-01 # change to etcd-02, etcd-03 on other nodes
Then add to /etc/hosts on all nodes:
192.168.1.11 etcd-01
192.168.1.12 etcd-02
192.168.1.13 etcd-03
Step 2: Download etcd Binaries
Run on all 3 nodes:
ETCD_VER=v3.5.12
curl -L https://github.com/etcd-io/etcd/releases/download/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz \
-o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
mkdir -p /tmp/etcd-download
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz \
-C /tmp/etcd-download --strip-components=1
sudo mv /tmp/etcd-download/etcd /usr/local/bin/
sudo mv /tmp/etcd-download/etcdctl /usr/local/bin/
sudo mv /tmp/etcd-download/etcdutl /usr/local/bin/
# Verify
etcd --version
etcdctl version
Step 3: Create etcd User and Directories
Never run etcd as root. Create a dedicated system user:
sudo useradd --system --no-create-home --shell /bin/false etcd
sudo mkdir -p /var/lib/etcd
sudo mkdir -p /etc/etcd
sudo chown -R etcd:etcd /var/lib/etcd
sudo chown -R etcd:etcd /etc/etcd
Step 4: Configure etcd on Each Node
Create /etc/etcd/etcd.conf on etcd-01:
name: etcd-01
data-dir: /var/lib/etcd
listen-client-urls: http://192.168.1.11:2379,http://127.0.0.1:2379
advertise-client-urls: http://192.168.1.11:2379
listen-peer-urls: http://192.168.1.11:2380
initial-advertise-peer-urls: http://192.168.1.11:2380
initial-cluster: etcd-01=http://192.168.1.11:2380,etcd-02=http://192.168.1.12:2380,etcd-03=http://192.168.1.13:2380
initial-cluster-state: new
initial-cluster-token: etcd-cluster-prod-01
log-level: info
On etcd-02 and etcd-03, use the same file but change name and the node-specific IP fields accordingly. The initial-cluster field stays the same on all 3 nodes.
Important:
initial-cluster-state: newis only for the first bootstrap. Once the cluster is running, this should beexistingon any node restart. Getting this wrong can cause a split-brain situation.
Step 5: Create a systemd Service File
On all 3 nodes, create /etc/systemd/system/etcd.service:
[Unit]
Description=etcd key-value store
Documentation=https://github.com/etcd-io/etcd
After=network.target
[Service]
User=etcd
Type=notify
ExecStart=/usr/local/bin/etcd --config-file /etc/etcd/etcd.conf
Restart=on-failure
RestartSec=5s
LimitNOFILE=40000
[Install]
WantedBy=multi-user.target
Start it on all 3 nodes within a short time of each other (they need to reach quorum together):
sudo systemctl daemon-reload
sudo systemctl enable etcd
sudo systemctl start etcd
Step 6: Verify the Cluster is Healthy
From any node:
etcdctl --endpoints=http://192.168.1.11:2379,http://192.168.1.12:2379,http://192.168.1.13:2379 \
endpoint health
Expected output:
http://192.168.1.11:2379 is healthy: successfully committed proposal: took = 3.456ms
http://192.168.1.12:2379 is healthy: successfully committed proposal: took = 4.123ms
http://192.168.1.13:2379 is healthy: successfully committed proposal: took = 3.891ms
Check the current leader:
etcdctl --endpoints=http://192.168.1.11:2379,http://192.168.1.12:2379,http://192.168.1.13:2379 \
endpoint status --write-out=table
Step 7: Test Data Replication
# Write to etcd-01
etcdctl --endpoints=http://192.168.1.11:2379 put /test/hello "devops-world"
# Read from etcd-02
etcdctl --endpoints=http://192.168.1.12:2379 get /test/hello
If you see devops-world back from a different node — your cluster is replicating correctly.
Step 8: Enable TLS (Must in Production)
The plain HTTP setup is fine for a lab. In production, always use TLS for both client and peer communication. At a high level:
- Generate a CA using
cfssloropenssl - Create server certs per node (with node IP as SAN)
- Create a client cert for
etcdctland the Kubernetes API server - Update config to use
https://and point to cert files
client-transport-security:
cert-file: /etc/etcd/certs/server.crt
key-file: /etc/etcd/certs/server.key
trusted-ca-file: /etc/etcd/certs/ca.crt
client-cert-auth: true
peer-transport-security:
cert-file: /etc/etcd/certs/peer.crt
key-file: /etc/etcd/certs/peer.key
trusted-ca-file: /etc/etcd/certs/ca.crt
peer-client-cert-auth: true
Full TLS walkthrough using cfssl is coming in the next post.
Backup etcd — Do This From Day One
# Take a snapshot
etcdctl --endpoints=http://192.168.1.11:2379 \
snapshot save /backup/etcd-snapshot-$(date +%Y%m%d%H%M).db
# Verify it
etcdutl snapshot status /backup/etcd-snapshot-<timestamp>.db --write-out=table
Automate with cron and ship to S3 or any object storage. If etcd goes down with no snapshot, the entire Kubernetes cluster state is gone. No second chances.
Common Issues and How to Fix Them
These are real problems you will hit at some point, not hypothetical ones.
Cluster not forming quorum after bootstrap
This is almost always a firewall issue. The nodes can’t reach each other on port 2380. Check it like this:
nc -zv 192.168.1.12 2380
nc -zv 192.168.1.13 2380
If it times out, open the ports in your firewall or security group and try again.
One node keeps crashing and restarting
Run journalctl -u etcd -f and read the logs carefully. The most common causes are:
- Wrong IP in
listen-peer-urlsorinitial-advertise-peer-urls - Leftover data in
/var/lib/etcdfrom a previous failed bootstrap attempt - Hostname not resolving properly in
/etc/hosts
If you’re starting fresh, it’s okay to delete the data dir and re-bootstrap — but never do this on a running cluster unless you know what you’re doing.
# Only on a node you are wiping and re-bootstrapping
sudo systemctl stop etcd
sudo rm -rf /var/lib/etcd/*
sudo systemctl start etcd
Leader election keeps flapping
etcd uses disk writes to commit log entries. If your disk is slow (spinning HDD, overloaded node), the heartbeat timeouts start triggering and the cluster keeps re-electing a leader. Always use SSDs for etcd nodes in production. You can also tune the heartbeat and election timeout:
heartbeat-interval: 250 # in milliseconds (default: 100)
election-timeout: 1250 # in milliseconds (default: 1000)
Increase these if your nodes are geographically spread out or on high-latency networks.
NOSPACE alarm triggered
etcd has a default backend quota of 2 GB. Once you hit it, etcd goes into read-only mode and starts throwing etcdserver: mvcc: database space exceeded errors. Kubernetes will effectively freeze.
Check if an alarm is active:
etcdctl --endpoints=http://192.168.1.11:2379 alarm list
If you see NOSPACE, compact and defragment:
# Get the current revision
rev=$(etcdctl --endpoints=http://192.168.1.11:2379 endpoint status --write-out=json | python3 -c "import sys,json; print(json.load(sys.stdin)[0]['Status']['header']['revision'])")
# Compact
etcdctl --endpoints=http://192.168.1.11:2379 compact $rev
# Defragment all nodes
etcdctl --endpoints=http://192.168.1.11:2379,http://192.168.1.12:2379,http://192.168.1.13:2379 defrag
# Disarm the alarm
etcdctl --endpoints=http://192.168.1.11:2379 alarm disarm
You can also increase the quota upfront in your config:
quota-backend-bytes: 8589934592 # 8 GB
Quick Reference: Key etcdctl Commands
| Command | What it does |
|---|---|
endpoint health | Check health of all endpoints |
endpoint status --write-out=table | See leader, Raft term, DB size |
put <key> <value> | Write a key |
get <key> | Read a key |
del <key> | Delete a key |
snapshot save <file> | Take a backup |
snapshot restore <file> | Restore from a backup |
member list | List all cluster members |
alarm list | Check for active alarms |
defrag | Defragment the backend DB |
compact <rev> | Compact old revisions |
How etcd Fits Into Your Kubernetes Control Plane
Just to close the loop on why all of this matters: when you run a kubeadm init or set up Kubernetes manually, the API server is configured to point to etcd using the --etcd-servers flag. Every object in Kubernetes — pods, services, namespaces, secrets, configmaps, RBAC rules — is stored as a key in etcd.
The keys look something like this:
/registry/pods/default/my-nginx-pod
/registry/secrets/kube-system/bootstrap-token-abcdef
/registry/deployments/production/api-deployment
When you do kubectl get pods, the API server reads from etcd. When you create a deployment, the API server writes to etcd. When the scheduler and controllers take action, they watch etcd for changes using a Watch API.
This is why etcd performance and availability directly translate into Kubernetes performance and availability. A slow etcd means a slow API server. A dead etcd means a dead cluster.
Monitoring etcd in Production
Once your cluster is up, don’t leave it unmonitored. etcd exposes Prometheus metrics out of the box on port 2381 (metrics endpoint).
# Add to your etcd config
listen-metrics-urls: http://0.0.0.0:2381
Key metrics to watch:
| Metric | Why It Matters |
|---|---|
etcd_server_is_leader | Know which node is the current leader |
etcd_server_proposals_failed_total | Failed Raft proposals — spikes mean trouble |
etcd_disk_wal_fsync_duration_seconds | Disk write latency — keep p99 under 10ms |
etcd_disk_backend_commit_duration_seconds | DB commit latency |
etcd_network_peer_round_trip_time_seconds | Peer-to-peer latency |
etcd_mvcc_db_total_size_in_bytes | DB size — watch before hitting quota |
You can import the official etcd Grafana dashboard (ID: 3070) into your Grafana instance and connect it to your Prometheus scrape config. Takes about 5 minutes and gives you a solid production dashboard immediately.
Final Thoughts
etcd is not complicated once you understand two things: it uses Raft for consensus, and it is the single source of truth for your entire Kubernetes cluster. Set it up carelessly and you will pay for it sooner or later.
Start with 3 nodes, always use odd numbers, enable TLS before you go to production, set up automated backups from day one, and put monitoring in place before something breaks — not after.
Once your etcd cluster is running healthy, you’ll actually feel a lot more confident about your Kubernetes infrastructure overall. Because now you understand the foundation everything is built on. Most engineers operate at the kubectl layer and never look deeper. The ones who understand etcd, the API server, and the control plane deeply are the ones who can debug anything and build truly reliable systems.
The ops work doesn’t start at the Kubernetes level — it starts with etcd.
Found this useful? Share it with your team. Next post: Setting up etcd with full TLS using cfssl — the production-ready way — and how to connect it to a Kubernetes cluster as an external etcd setup.
Official Documentation
- etcd Official Docs → https://etcd.io/docs/
- etcd GitHub Repository → https://github.com/etcd-io/etcd
- etcd Releases (GitHub) → https://github.com/etcd-io/etcd/releases
- etcd Raft Consensus Algorithm → https://raft.github.io/
Kubernetes Official References
- Kubernetes etcd Cluster Setup Guide → https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
- Operating etcd for Kubernetes → https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/
- Backing up an etcd Cluster → https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#backing-up-an-etcd-cluster
TLS & Security
- cfssl GitHub (for TLS cert generation) → https://github.com/cloudflare/cfssl
- etcd Transport Security Model → https://etcd.io/docs/v3.5/op-guide/security/
Monitoring & Metrics
- etcd Metrics Reference → https://etcd.io/docs/v3.5/metrics/
- Grafana Dashboard for etcd (ID: 3070) → https://grafana.com/grafana/dashboards/3070
- Prometheus etcd Scrape Config → https://etcd.io/docs/v3.5/op-guide/monitoring/